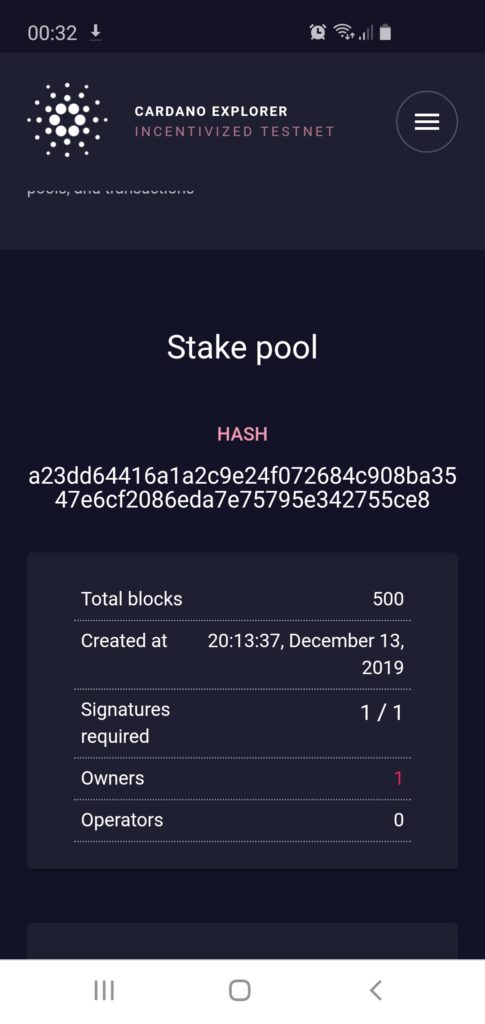
 ADA North Pool
ADA North PoolI tought I would share my current screen setup on the server. I am using terminator bash terminals and hardware monitoring is your standard stuff like Glances, Htop and Iotop. But also I use Chrony for making sure my system clock is up to date and tuned to make sure my network is up to date, both running as services on the computer. I had my own custom made scripts for forking / bootstrap checking but replaced them with the great script Redoracle made. I also run Prometheus, Grafana and Nginx for monitoring and websites and a few security measurements, one of them that I think its fine to mention is I run Fail2ban. I have removed some information that could affect security and replaced with a red bar.
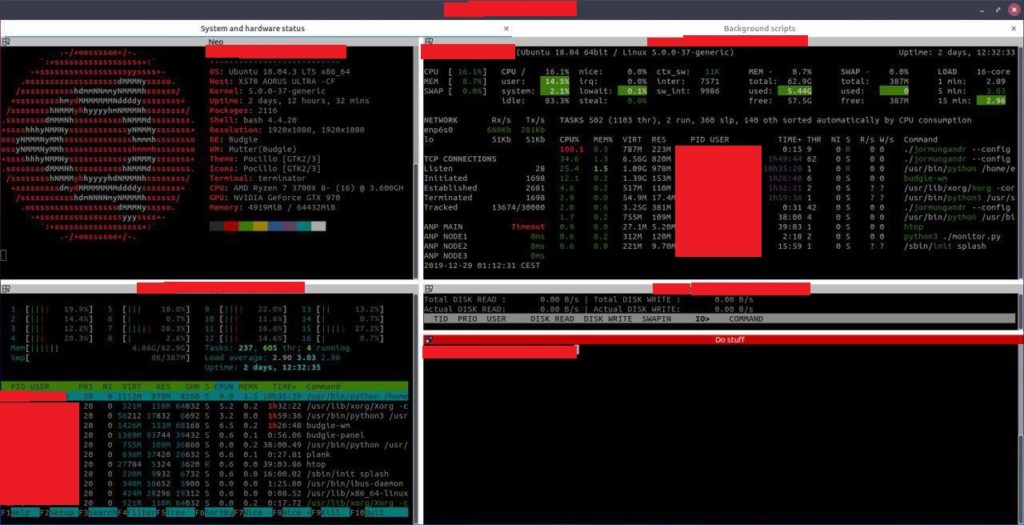
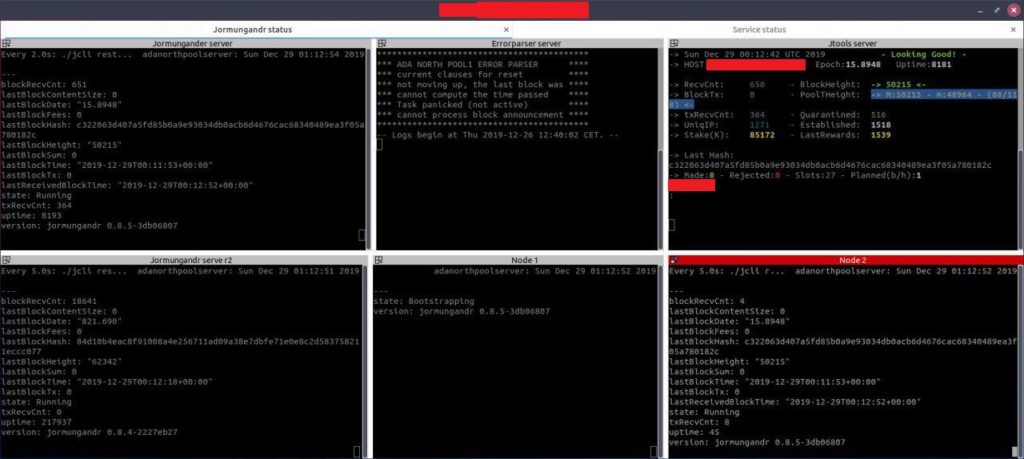
Celebrating a milestone for ADA North pool we have come a long way since epoch 1 and 2 where we produce one block in each epoch! We have tweaked the numbers even more when it comes to connection settings and believe we have found a sweet spot that will give us even more optimal operations.
To keep everything running smoothly we upgrade to latest packages for our webserver technology and we also added chronyd to make sure our server keeps running at correct time (in millisecond measurement ranges) while also adding maintenance software that automates upgrades and keeps the system tuned and performing over time.
I compiled 0.8.5 because the pre-compiled options do not offer Journald log support and you can get this if you compile the binaries yourself.
Having read several TCP networking guides and doing tweaks adjusting to any – at the moment – type of challenges I realized this would be very time consuming. I am trying to set up as much automation as possible so the server is robust. In that regard we found https://tuned-project.org/ and it has had already dramatic results cutting cpu usage in half and allowing us to double our network connectivity without any networking errors.
Had another long night where I tweaked the node cluster (less nodes but more quality to each nodes with more connections and file limits for each) and also optimized the server painstakingly reducing one by one some metrics I know affects the quality the serer has to read and process incoming connections fast until I found an optimal point. After this the server seems again more stable (hoping this time it is going to last for a while!)
Now with the server more stable I have had some time to add more “bells and whistles” type of features so I have now not only a hardware monitoring but also a Jormungandr server monitoring that user can look how the server is doing right here on the web page, I have added these as menu links. As always feel free to contact me for encouragement / suggestions.
With a very high input/output for our files I have decided that its more important with NVME SSD performance for input output file operations than 4Terrabyte of RAID and will likely switch over to full NVME hardware if we are successful in the Testnet period. It also has the side benefit of a 90% less watt usage per disk.
To improve system performance we have added several tweaks and also some software that will help us better handle large connection loads that is needed to keep having an “overview” of the network that will help our server not following forks. One such measure is the google BBR algorithm that has been tried and tested by a major corporation in high stress situations. https://cloud.google.com/blog/products/gcp/tcp-bbr-congestion-control-comes-to-gcp-your-internet-just-got-faster
Hopefully epoch 7 will be a good one! To be sure we are still following with dedication and keep improving the network performance looking under any stone we can find.
I had to pull an all nighter as even while the new cluster of nodes is helping out a lot in stability it did not help when there where suddenly a strong propagation in the network for several forks. To help with this issue we also increased the network capacity of the main server so now it sees most of the active nodes in the network. This allows the server to look at what is the longest chain and correctly identify what path to take regarding forks.
Also when you look at the numbers we had an amazing performance. We lost some blocks during the early time period of forks but around 4 AM (as I told I did an all nighter for this) after also bootrapping to the nearest IOHK servers (3 servers are located in EU) and implementing these changes the pool performed admirable. Lets look at the math:
We know that 4320 blocks are on offer each epoch (10% of the total 43200 slots) We also know that currently only around half of this is actually produced by pools (around 2600). In our case we have a stake of around 66 million delegated to us and 0.95% of the total stake. With 4320 blocks we should with 0.95% recieve 41 blocks. Guess how many blocks ADA North Pool produced during the epoch? 41! So overall given all that happened epoch 6 I am actually very pleased with the performance and keep in mind that performance matric is a short term performance metric, you should also ask yourself the question how many blocks is this pool producing compared with its stake?