ISPPA – Inter Stake Pool Peering Agreement
In spirit with the Cardano incentivised testnet and experimenting on models of pool operation several pools have together formed an “Inter-Stake Pool Peering Agreement”
In total these pool operators have produced well over 42000 blocks all together and have proven over time to be reliable pool operators securing 24/7 operations of their pools. For comparison this is roughly the same size as all the blocks produced by the largest multi pool combined. On average the pool operators produce around 12% of the blocks in the network in any given epoch.
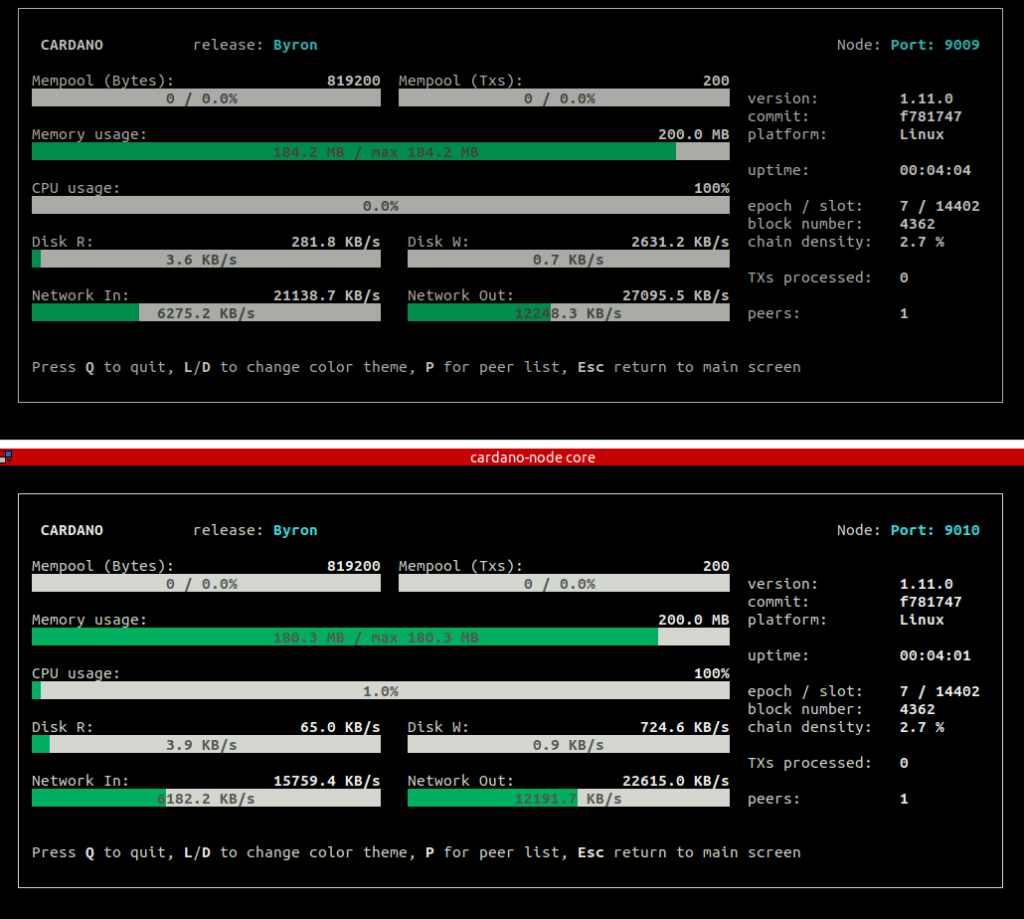
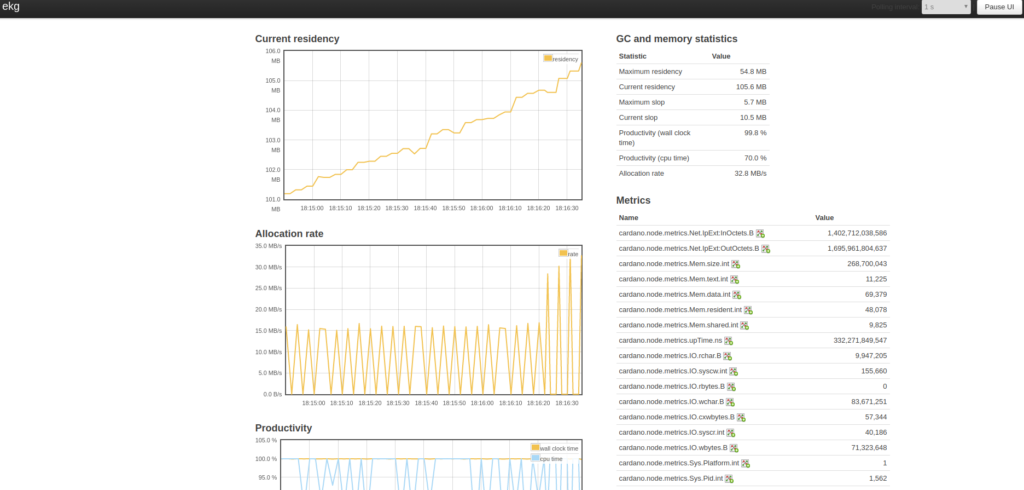
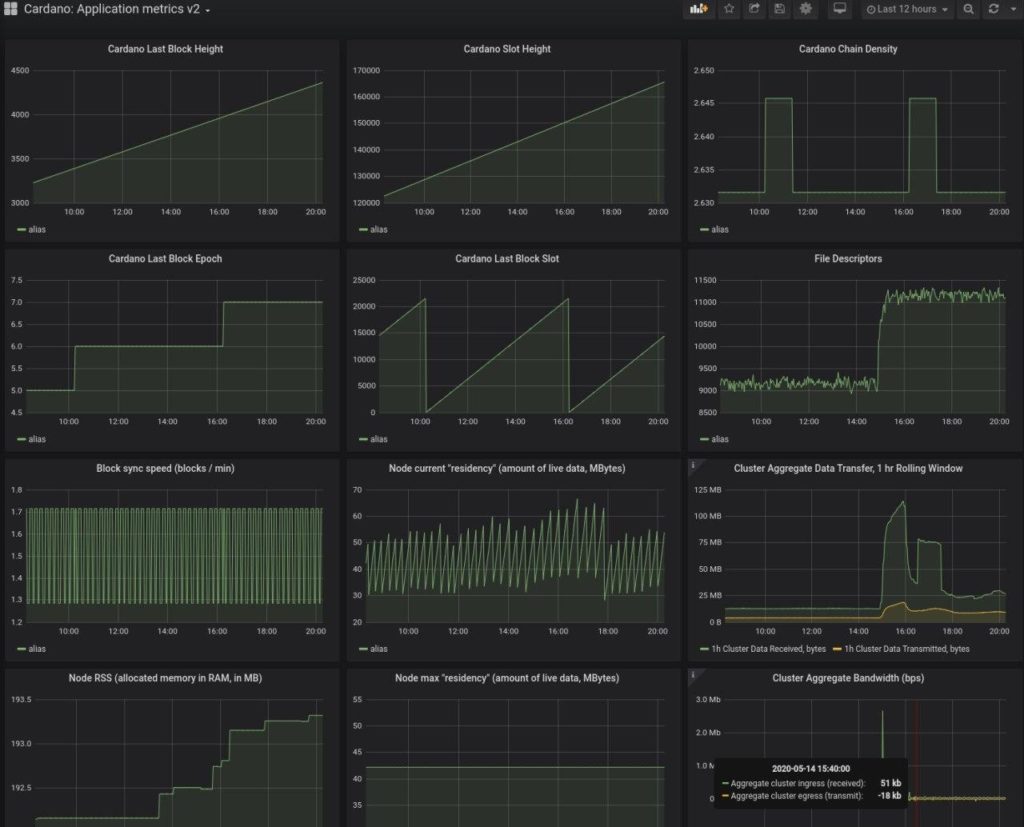
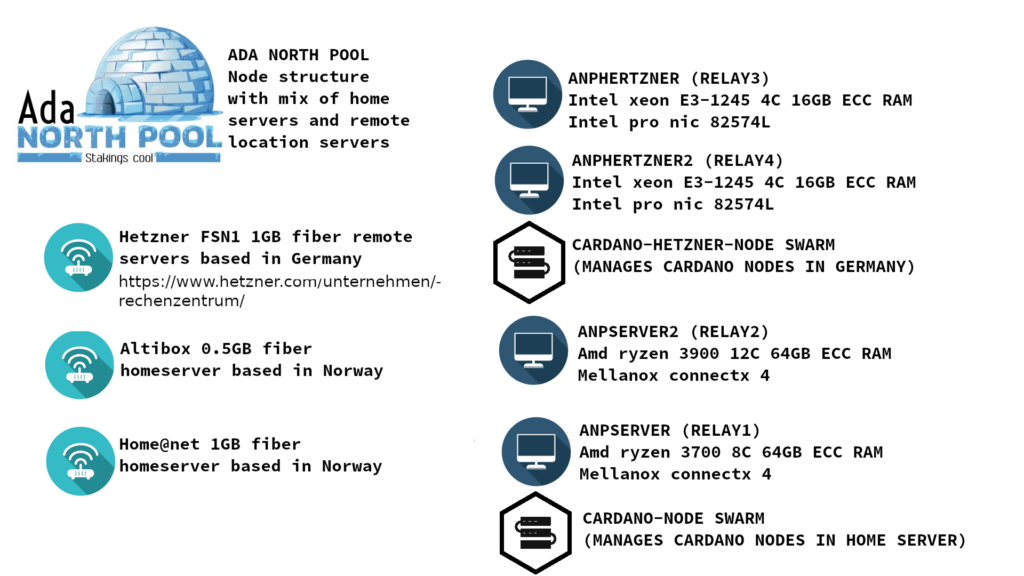
The main intention of this agreement is to test for and try to achieve an even better networking infrastructure and propagation of blocks than with each pool operator running on his own during the ITN. It involves connecting the pools and relay nodes as preferred meaning that these nodes will form a huge cluster located all over the world that will be constantly inter-connected and exchanging data. The preferred option technically adds a fourth layer of communication on top of the 3 communication layers of Cyclon, Rings and Vincity. It does not mean that the pool operators are going to exclude other pools from their information flow as we are firm believers in decentralization. It also does not mean the operators are running a common business but will stay independent entities.
Finally as this is an ITN we hope to collect data and see if this model of operation can give improvements to the already steadily improving network of Cardano nodes all around the world! We will welcome collaboration at a later point but for now want to keep a steady sample size to compare data.
Pool operators AHLNET AIJOU ANP BAKE BAKE2 BCSH CALM CHEAP CHKN CLIO1 COOL CSP ELMO HAPPY HRBR HRMA HRMS ITALY KIWI LIEBE LOVE MERRY MONKY SAND SEXY SEXY69 SOBIT STACK STDN STR8 VIPER
https://isppa.info/